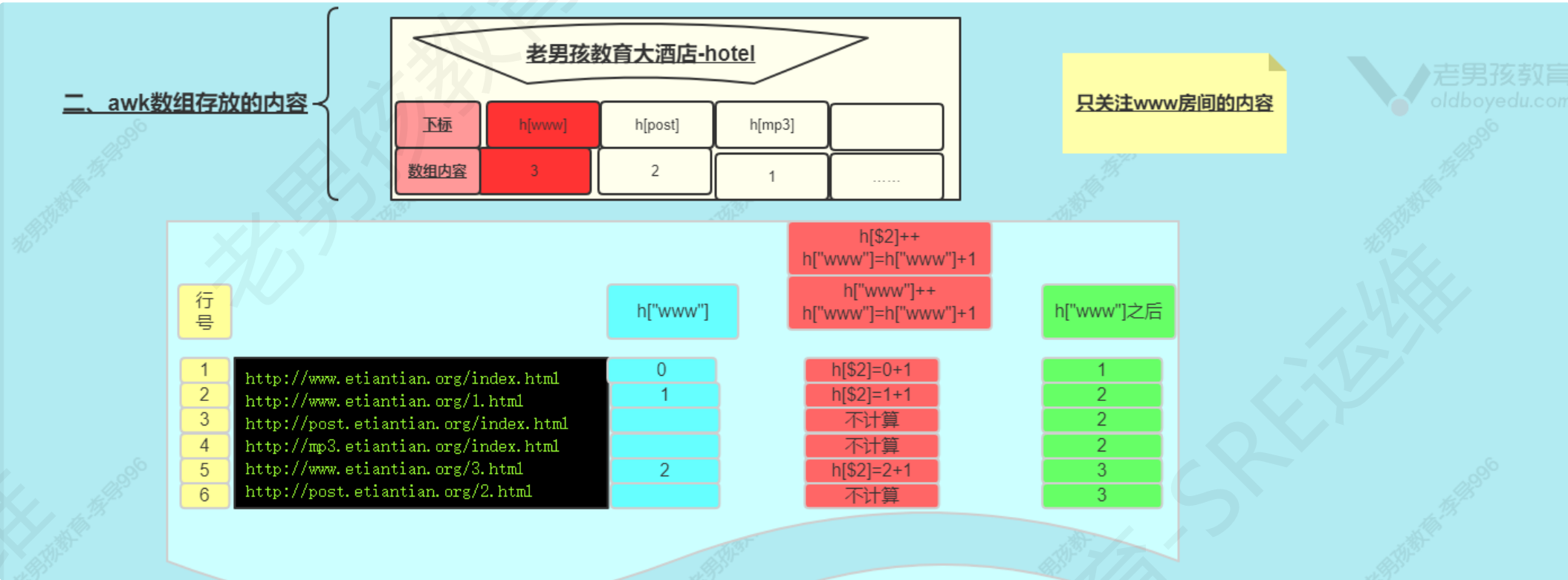
shell脚本执行方式
#!指定脚本的命令解释器
bash—-#!/bin/bash
python—-#!/usr/bin/python或#!/usr/bin/env python
Ubuntu/Debian系统中自带dash,使用sh执行脚本会自动用dash
使用bash运行脚本会创建一个子shell进程执行,通过.或source执行脚本会在当前命令中直接执行(需要在当前环境下生效)
所以配置系统环境变量之后用source加载
命名规则:不能以数字开头,取名尽量有意义,几个单词之间用下划线_连接,如01.check_user_exist.sh
分类:
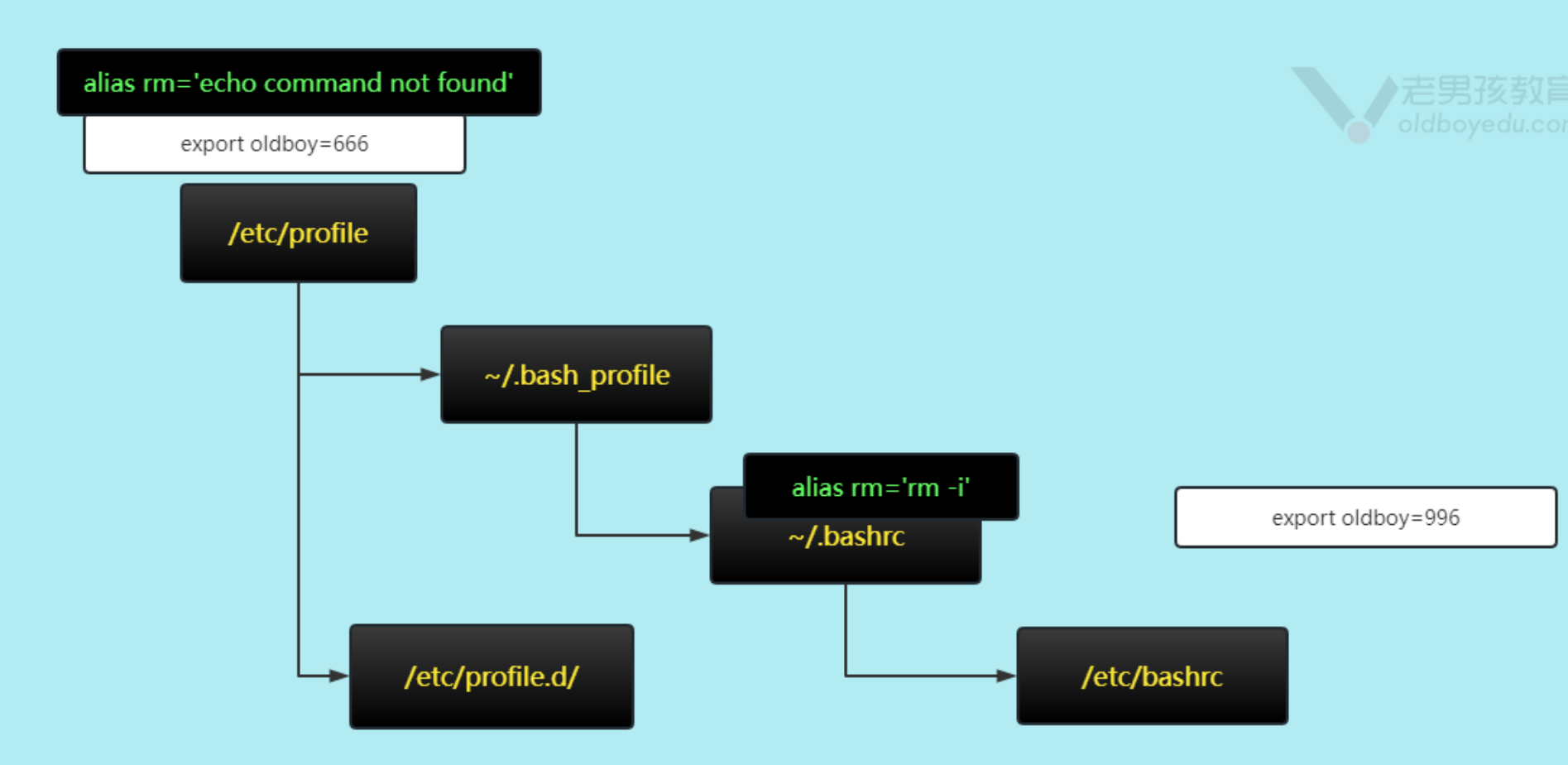
普通变量(用户局部变量)~/.bashrc ~/.bash_profile
环境变量(全局变量),系统自带 env命令查看系统所有全局变量,一般名字为大写字母(PS1)–/etc/profile
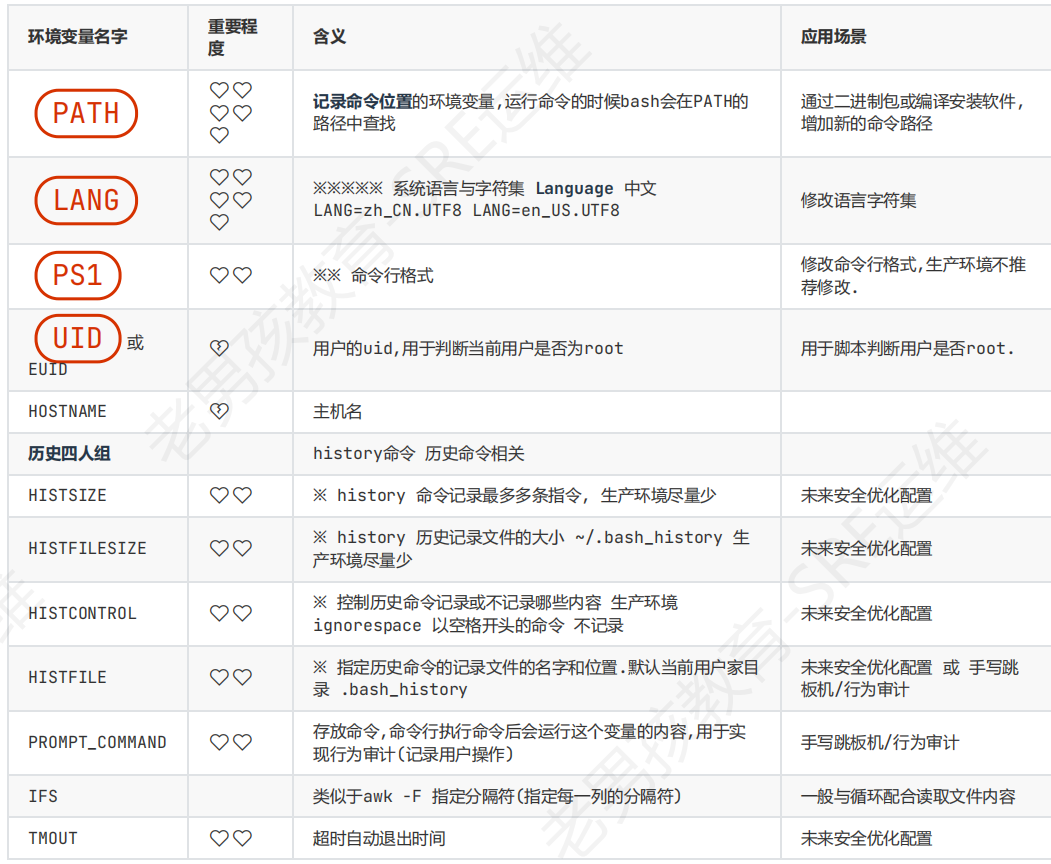
环境变量文件读取(加载)顺序
特殊变量(常用):方便对参数,命令结果进行判断和对比
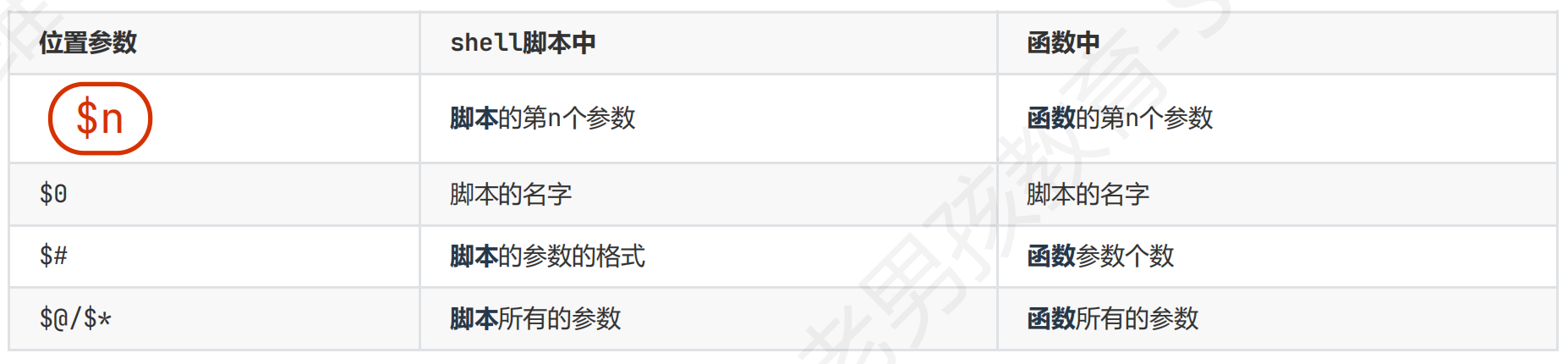
1.位置相关的特殊变量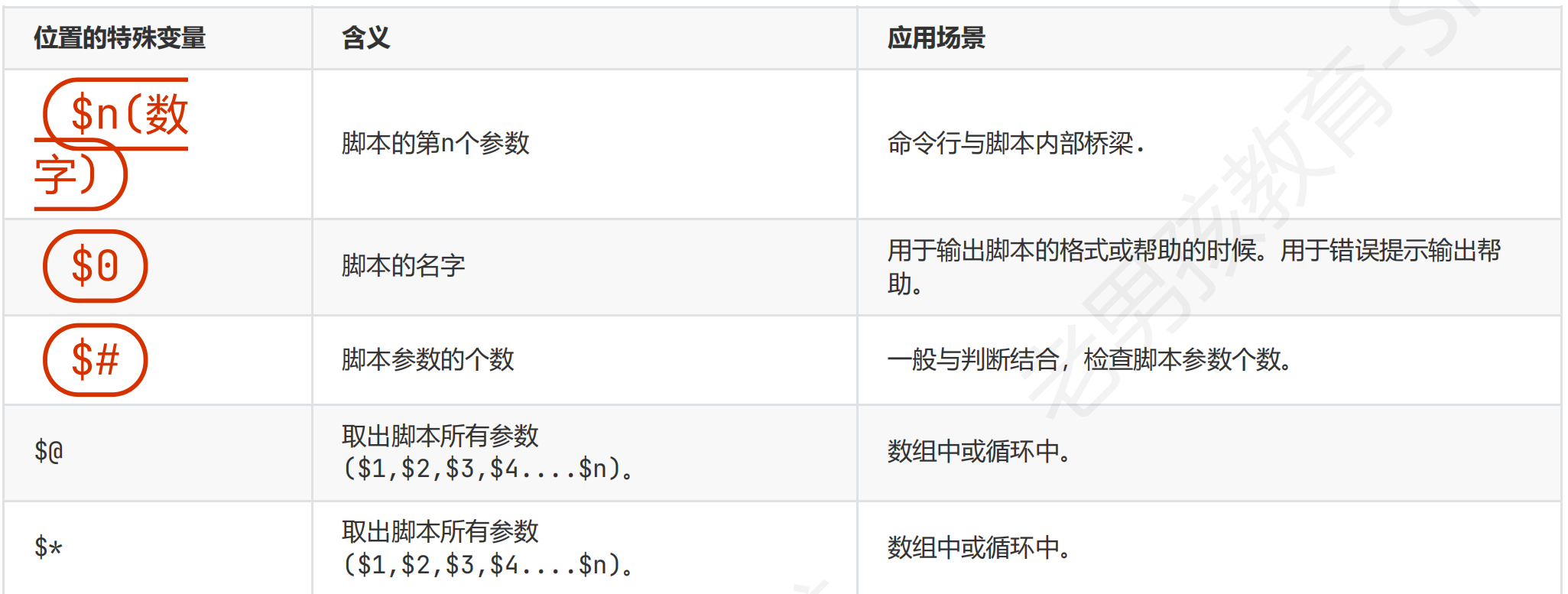
$n n>9 会表示为$1+0 第一个参数+0,使用${11}表示即可
当以上的变量在if中做判断时候,会用到比较运算符
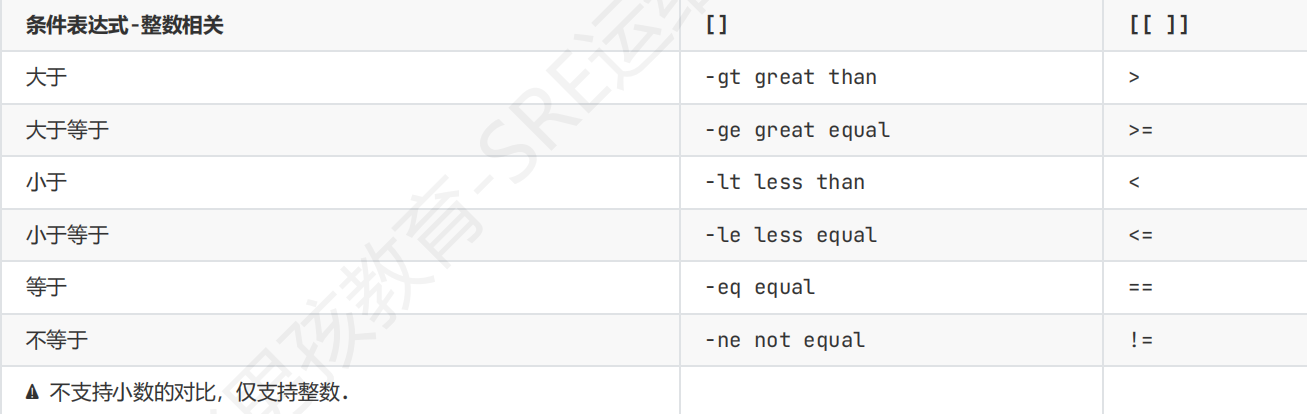
-eq =/== 等于 equal
-ne != 不等于
-lt < 小于 less than
-le <= 小于等于 less equal -gt > 大于 great than
-ge >= 大于等于 great equal
当if [ $? -eq 0 ]时,=会默认进行字符串比较,而eq会做整数的数值比较,-eq:效率更高:=:字符串比较,变量为空会报错,效率低
$@和$*相同点:取出脚本执行时输入的所有参数,大部分和循环一起用作为for i in “$@”
只有二者都在循环中且都用””时
“$@”:所有参数是独立的参数,有几个就循环几次
“$*”:所有参数是一个参数,只循环一次
shift 移动,参数向左移动一位
状态相关的特殊变量
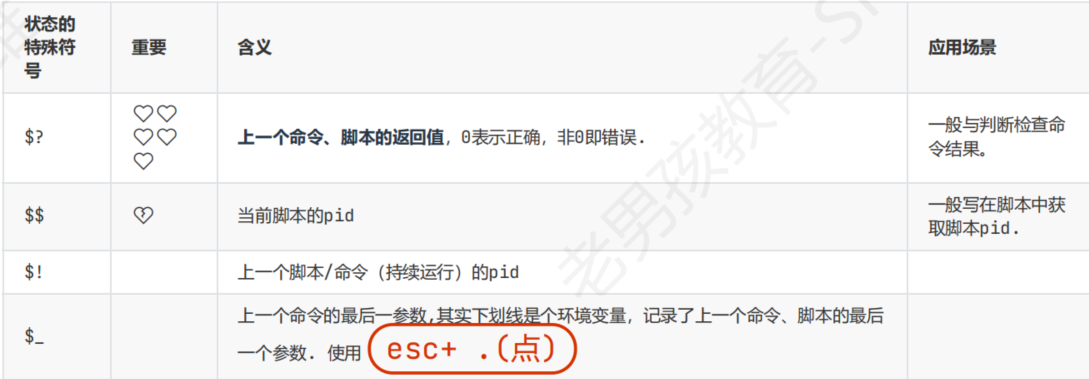
${#变量}:统计变量的字符数== echo $a | wc -L
${变量/变/量}→把变改成量→量量== echo $a | sed ‘s#变#量#g’
变量子串:用于对变量处理加工,(统计变量中字符串数量,对变量内容进行替换/删除….)
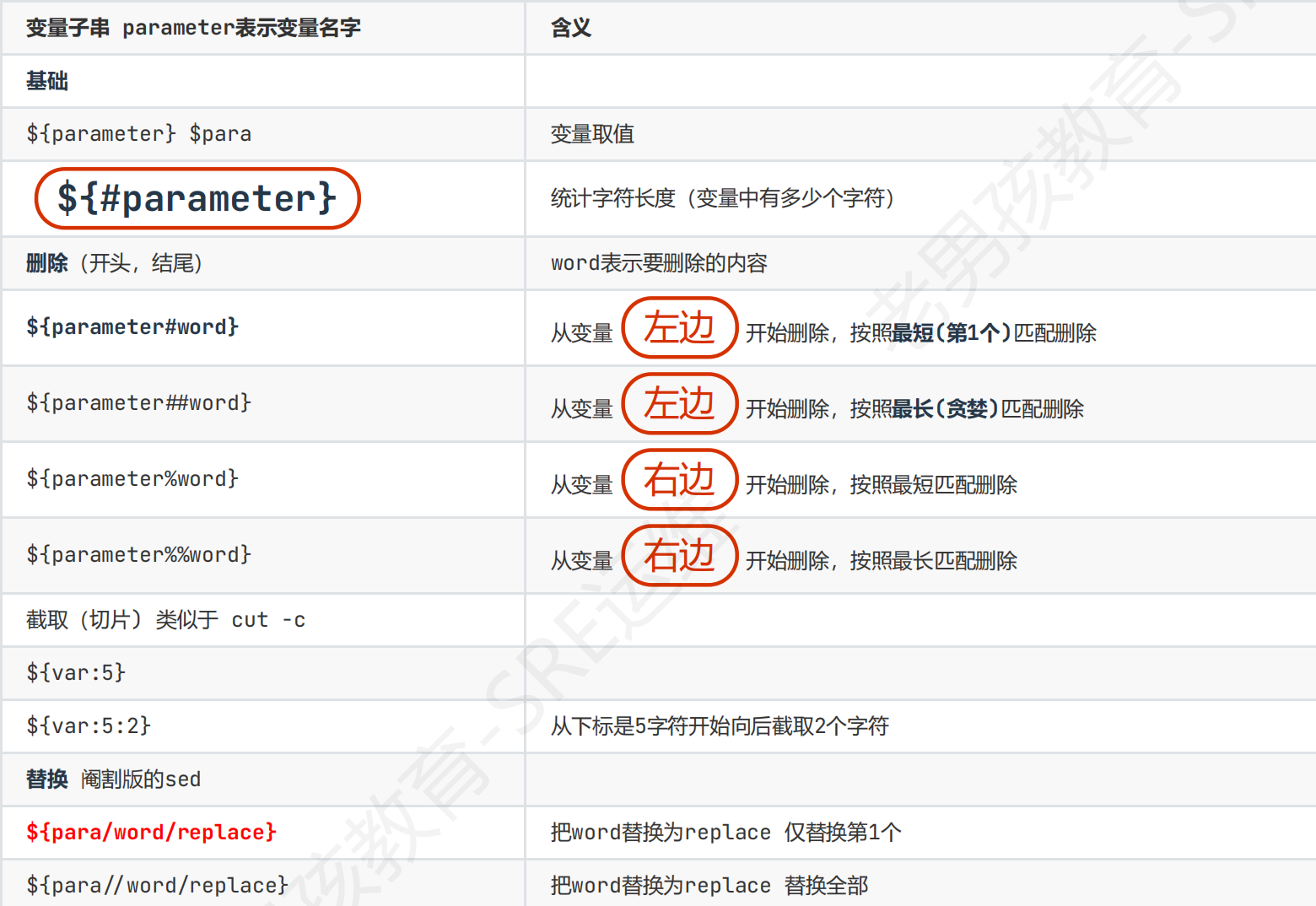
变量子串
格式${变量},写为$变量格式无法识别
应用:可以不用,但是这个效率高
截取,切片功能
等同于cut -f 1—取一行中的第一列(第一个字符)
cut -c 1-3—取1-3个字符
var=zhangpeng 将每个字符做标记
zhangpeng对应第012345678个字符
echo ${var:1} hangpeng —从第1个字符开始显示
echo ${var:1:2} ha —–从标记为1的开始取2个字符
echo ${var:1:3} han—–从标记为1的开始取3个字符
替换功能:
echo ${var/eng/111} zhangp111
等同于
echo $var | sed ‘s#eng#111#g’
统计变量中字符个数功能
echo ${#var} 9
等同于
echo $var | wc -L


运算符
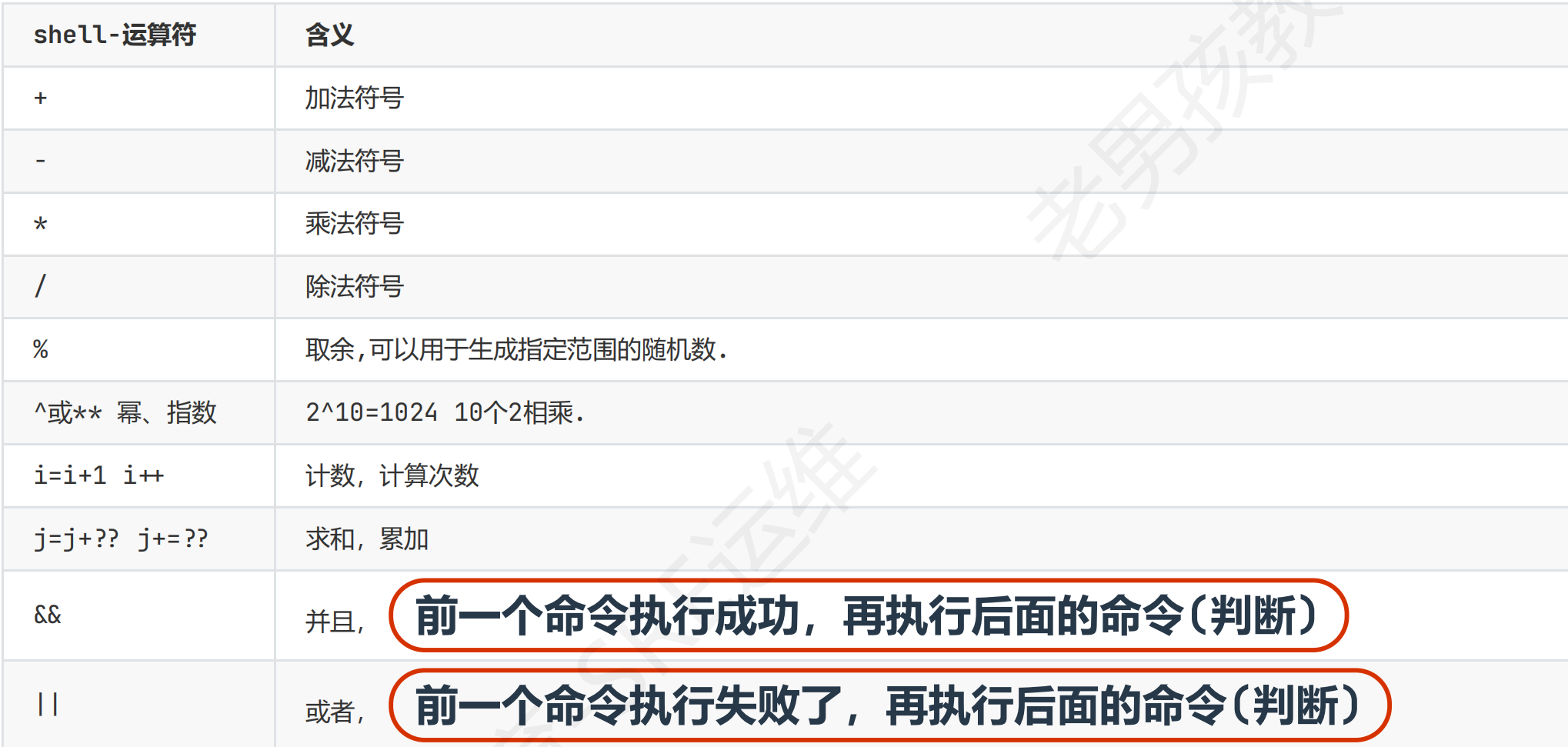
运算方法(工具):推荐用awk;bc -l默认20位小数点精度且省略小数点前的0
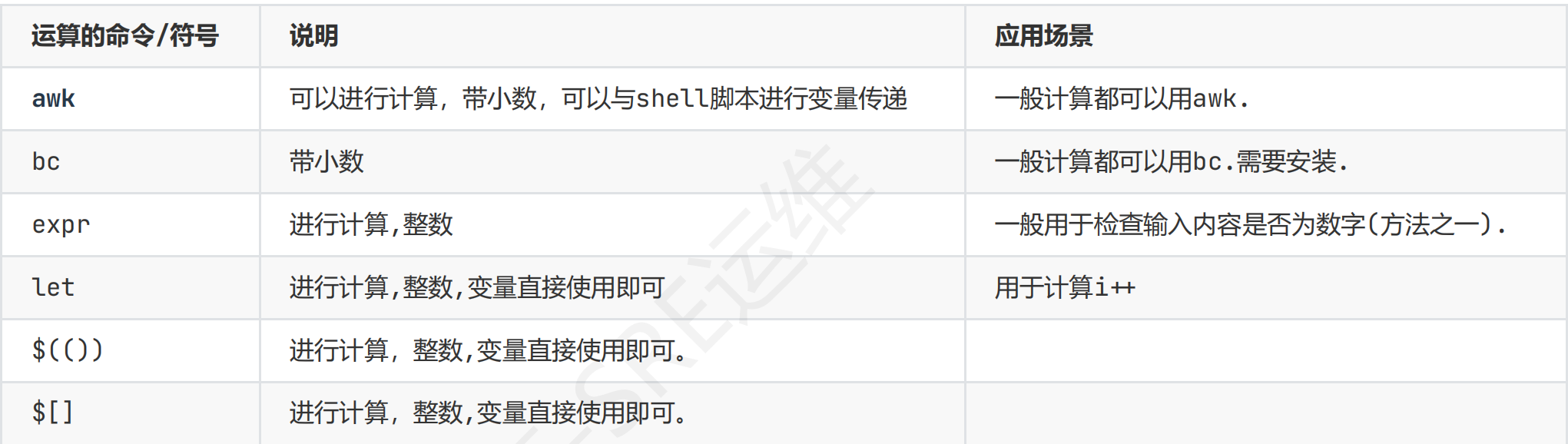
awk计算
awk ‘BEGIN {print 1/3}’ 在读取文件之前运行,后面不接文件
1.直接运算awk -v total=4000 -v userd=2000 ‘BEGIN {print used/total}’
2.运算变量(常用)total_mem=4000,used_mem=2000
awk -v a=$total_mem b=used_mem ‘BEGIN {print b/a}’
bc计算:需要以echo “” | bc -l的形式
echo “2000/4000” | bc -l
echo “$used_mem / total_mem” | bc -l
用bc计算乘法时必须加上echo后面的””或者加上转义字符\:echo ” a * b”/echo a\* b | bc,否则*会被当初通配符报错
expr–作为是否是数字的检查
正常使用计算:格式为expr num1 + num2
使用*做乘法运算报错的原因:当前目录下有文件就会执行失败,需要添加转义字符\*才能正常运算
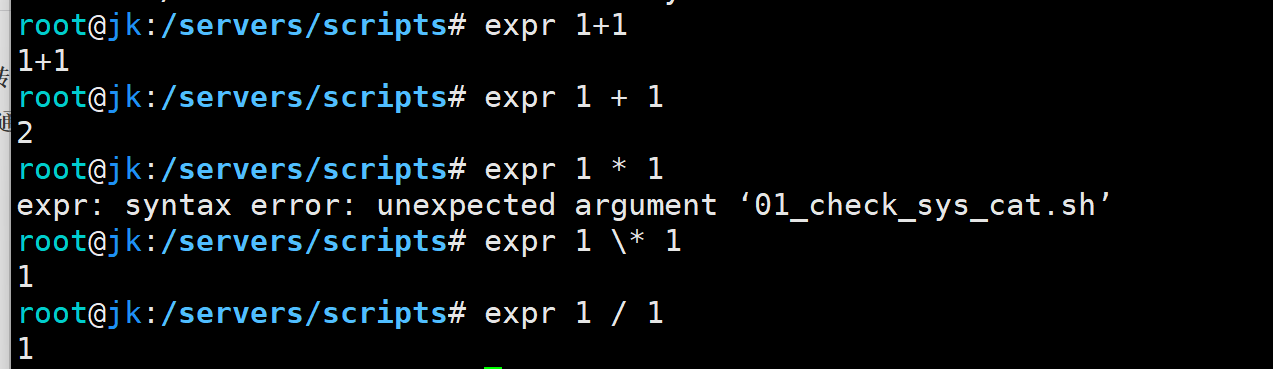
实现方法:查看 (expr + 变量) 的返回值
如果返回值为0或1,说明命令正常执行,变量是数字
如果与返回值为2或3…,说明命令执行失败,变量不是数字
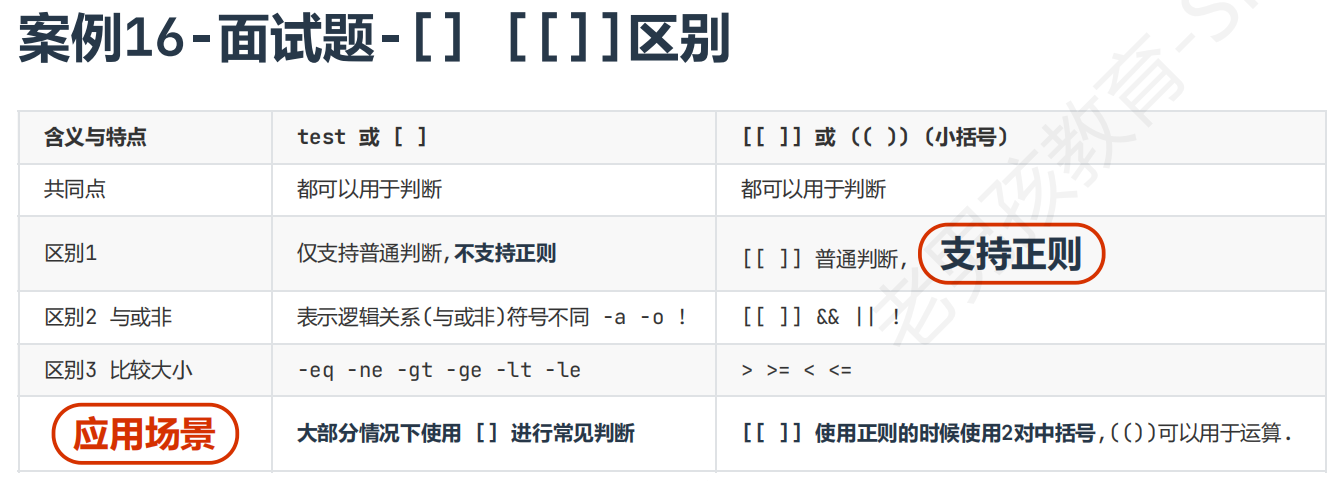
条件表达式(最基础)
属于判断中的核心,if后面都在用它,可以和&& ||一起用
目标:熟练掌握格式,根据判断目标选择用哪种格式(文件、大小、字符串、与或非),[]中写-a的格式少用,可能引起歧义,&比|的优先级更高
[ $1=n -a $2=n ] ==== [ $1=n ] && [ $2 = n ]
[[ $1=n && $2 = n ]] ==== [[ $1=n ]] && [[ $2 = n ]]
案例16:[] 与 [[]] 区别
常用条件表达式符号表

整数比大小符号表
对比字符串:必须在=两侧的内容加””
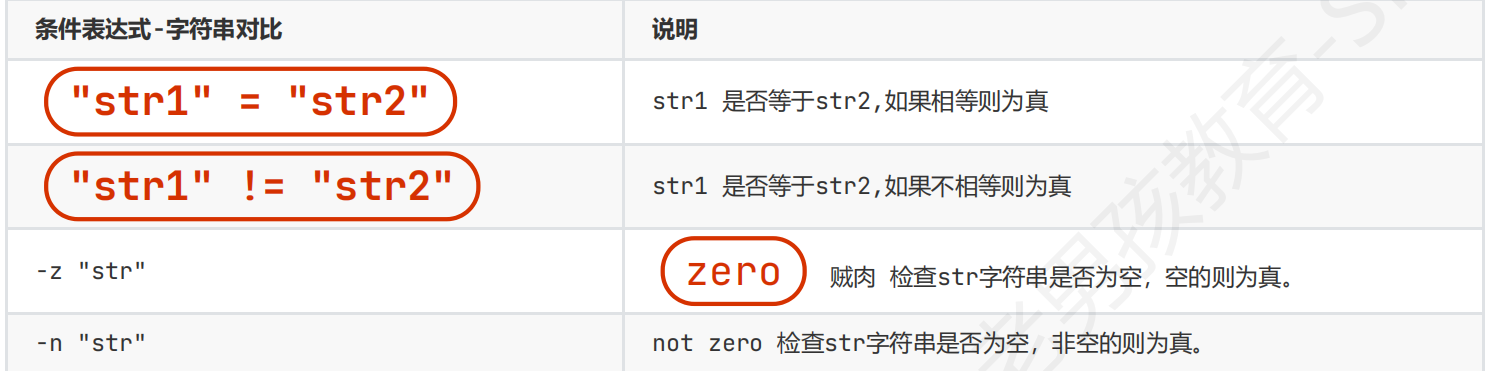
-z 是否为空,为空则真
-n是否不为空,不为空则真
两个条件同时满足用逻辑判断表示(与或非)

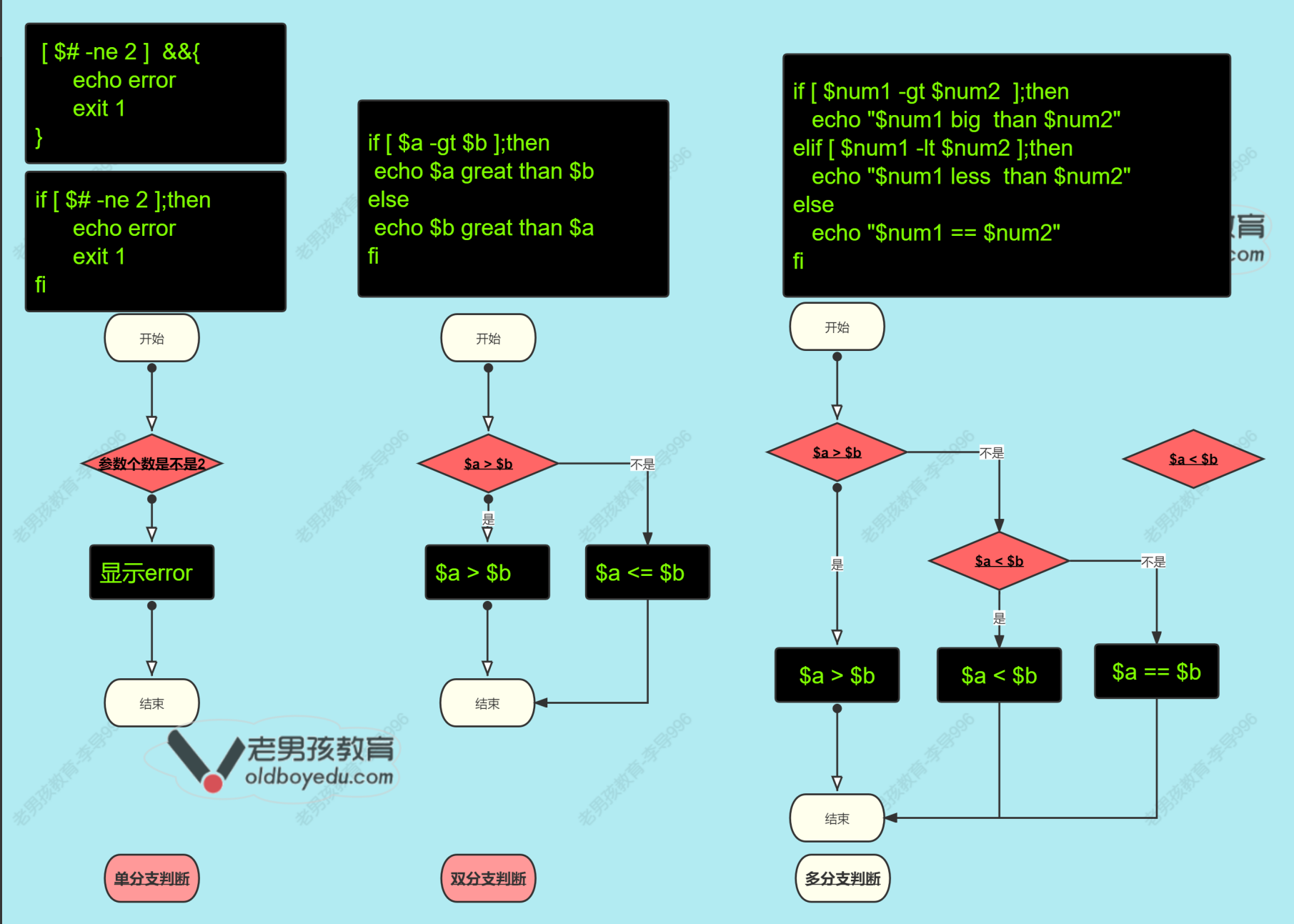
if判断 三种格式
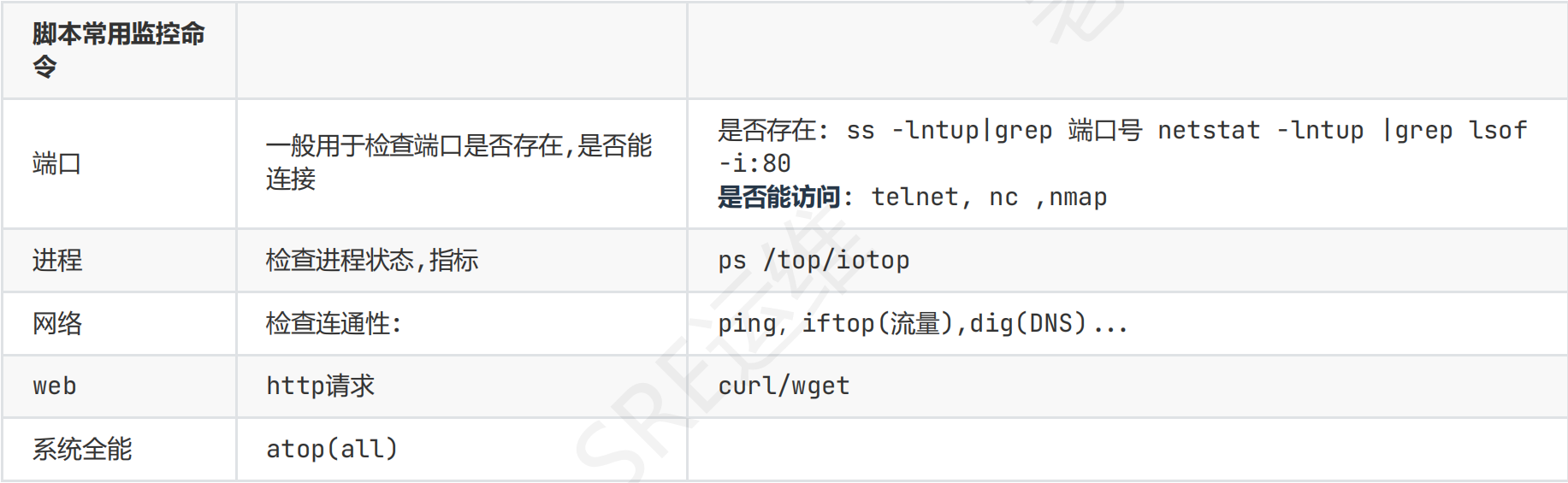
脚本中常用命令
for/while/dountil区别

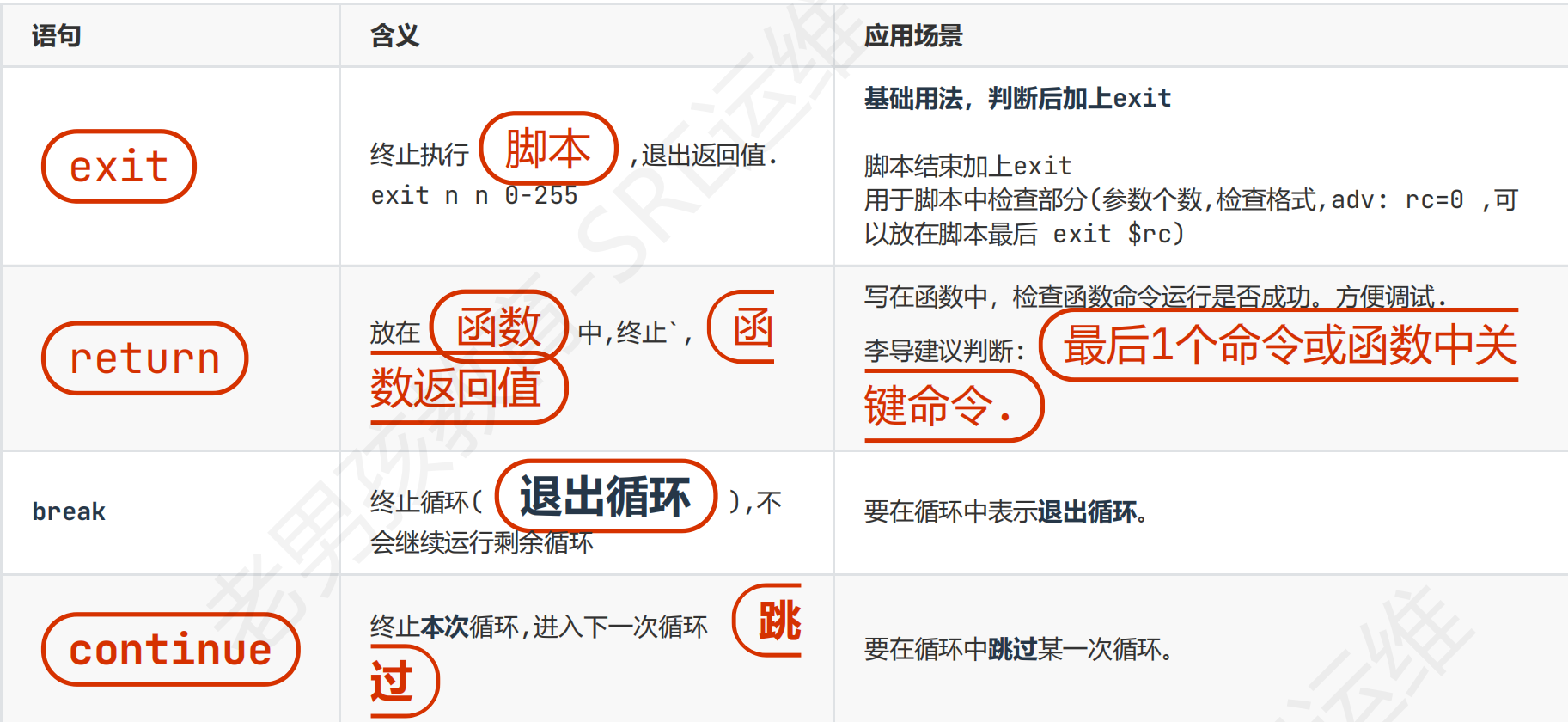
循环控制语句:exit/return/break/continue
shell数组创建和赋值
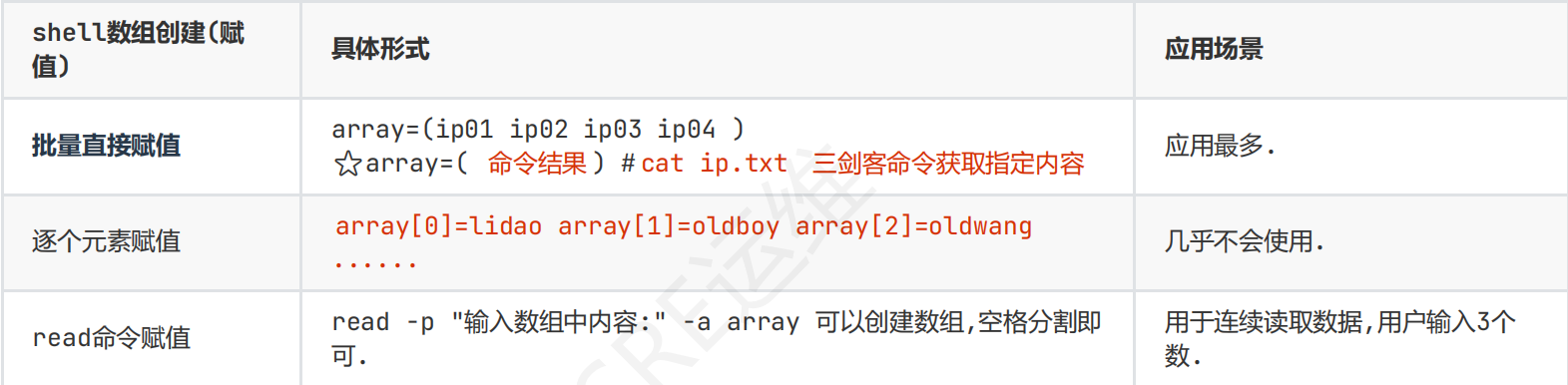
批量直接赋值
格式:ip_array=(1 2 3 4),中间至少一个空格分割
取值格式(数组的使用):
${数组名[下标]}
数组中从第一个数到第n个数,下标从0开始,分别是0,1,2…n-1,
eg:${ip_array[0]}=1 ${ip_array[3]}=4
将数组中的内容一次性全取出来之后做处理(这里用for循环输出)
${数组名[@或*]}
eg:
for n in ${ip_array[@]}
do
echo -n "$n "
done
结果:输出数组内容1 2 3 4
逐个赋值(几乎不用):
格式:array[0]=baidu array[1]=jd array[2]=taobao.....
read命令赋值
用于连续读取用户输入的空格分割的数据存放在一个数组中:read -p "输入提示:" -a 数组名
方法一:使用 mapfile 和数组
mapfile -t code_src_name < <(find "$code_src_dir" -type f)
for file_path in "${code_src_name[@]}"; do
# 处理每个文件
done原理解析:
mapfile(或readarray):内置命令,专门用于将输入读入数组-t选项:移除每行末尾的换行符< <(...):进程替换,将find命令的输出作为文件描述符传递给mapfile将所有文件名一次性加载到数组
code_src_name中然后使用
for循环遍历数组
方法二:使用 while read 循环
while IFS= read -r file_path; do
# 处理每个文件
done < <(find "$code_src_dir" -type f)原理解析:
while IFS= read -r file_path:逐行读取输入IFS=:防止行首行尾的空格被修剪-r:防止反斜杠转义
< <(find ...):将find命令的输出作为输入流每次读取一行(一个文件名),立即处理,不存储在内存中
两种方法的对比
| 特性 | mapfile + 数组 | while read 循环 |
|---|---|---|
| 内存使用 | 高(所有内容加载到内存) | 低(逐行处理) |
| 执行速度 | 通常较快(一次性加载) | 稍慢(逐行处理) |
| 文件数量 | 适合文件数量较少的情况 | 适合文件数量多或无限流 |
| 错误处理 | 如果中间出错,所有数据已加载 | 可以在任何点停止,减少资源浪费 |
| 代码可读性 | 更清晰,分两步:加载→处理 | 更紧凑,加载和处理合并 |
| Bash版本要求 | 需要 Bash 4.0+ | 几乎所有 Bash 版本都支持 |
哪种方法更好?
推荐使用 while read 循环的情况:
文件数量很多时(避免内存耗尽)
处理大型目录结构时
需要实时处理流数据时
希望更早开始处理(不需要等待所有文件找到)
兼容旧版本 Bash(< 4.0)
推荐使用 mapfile 数组的情况:
文件数量较少时
需要多次遍历同一文件列表时
需要随机访问数组元素时
代码可读性更重要时
确定使用 Bash 4.0+ 时
实际应用建议
对于收集文件内容的场景,推荐使用 while read:
完整脚本:get_codes.sh重要改进:处理特殊文件名
上面的脚本使用了 -print0 和 -d '',这是处理包含空格、换行符等特殊字符文件名的正确方法:
find -print0:用 null 字符(\0)分隔文件名,而不是换行符read -d '':读取直到 null 字符,而不是换行符
性能测试示例
# 测试 mapfile 方法
time {
mapfile -t files < <(find . -type f)
for file in "${files[@]}"; do
: # 空操作,只是遍历
done
}
# 测试 while read 方法
time {
while IFS= read -r file; do
: # 空操作,只是遍历
done < <(find . -type f)
}总结
对于读取find命令执行结果的方案,while read 循环是更好的选择,因为:
更节省内存(特别是文件很多时)
更安全(处理特殊文件名)
更早开始处理文件
更好的错误恢复能力
只有在确实需要将文件列表保存在数组中供后续多次使用时,才选择 mapfile
案例44:把案例30改为数组形式,从server/files/urls.txt读取内容
44_check_ip_func.sh
案例30的脚本中urls变量不是数组,而是一个空格分割的字符串,for循环处理时正好将每个域名分割开,得到了类似于处理数组中每个元素的效果
urls.txt:
10.0.0.200
jd.com
baidu.com
taobao.com
linuxjk.cn
12306.cn
脚本思路:原脚本利用手动输入+循环的思路进行判断输入的信息中每个域名是否能ping通,现在需要修改成将文件里的域名传入数组,再进行数组的处理,即测试是否能ping通
1.创建文件位置的变量file
2.将文本信息传入数组:urls=$(cat $file)
检查数组是否为空,如果为空说明解析失败(没有文件或文件没有内容,此处没有进行是否为域名的正则匹配,可以将匹配之后得到的域名信息数组进行下一步处理)
3.进行处理:for url in ${urls[@]}
ping -c1,用$?获取返回值,0则输出成功,1则失败