按e进⼊图2页面,原配置如图所示。
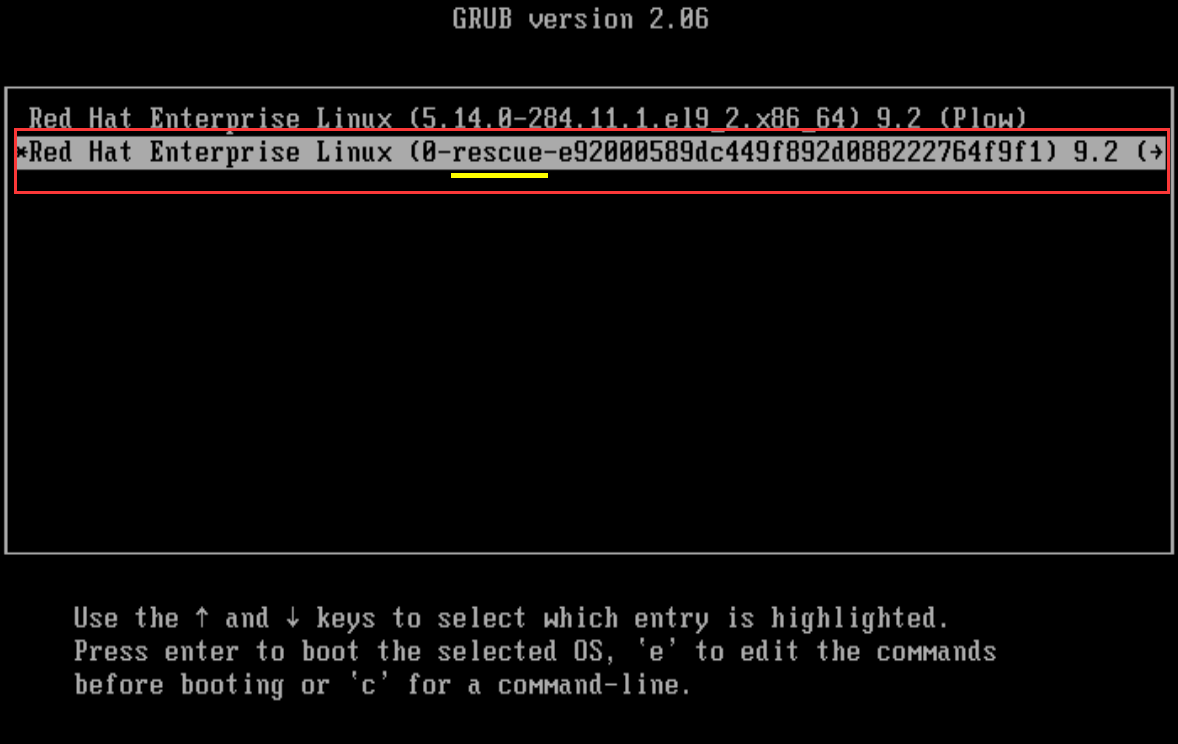
修改原配置为红色框选部分,如图⼆所示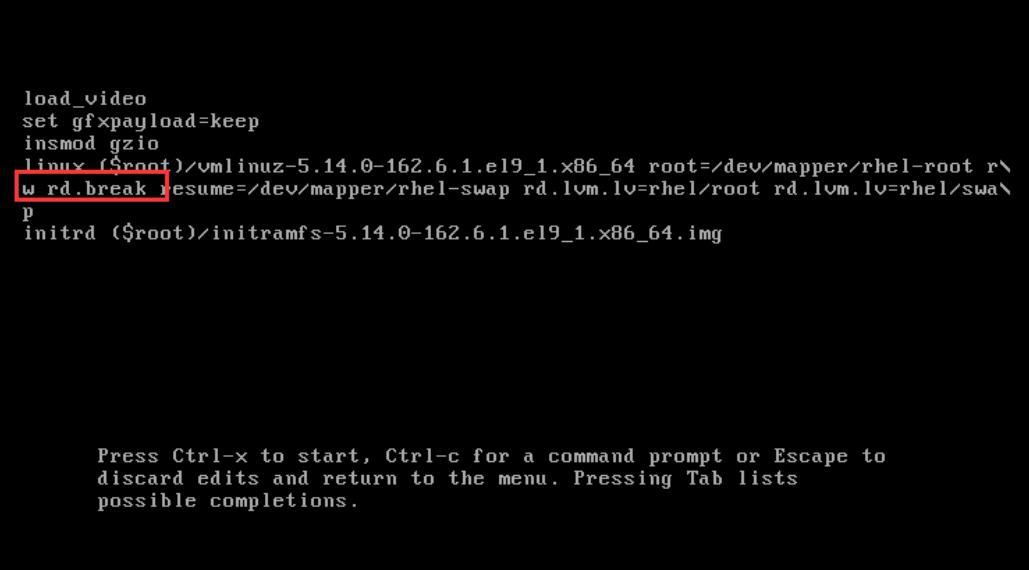
然后按ctrl+x,执行以下命令
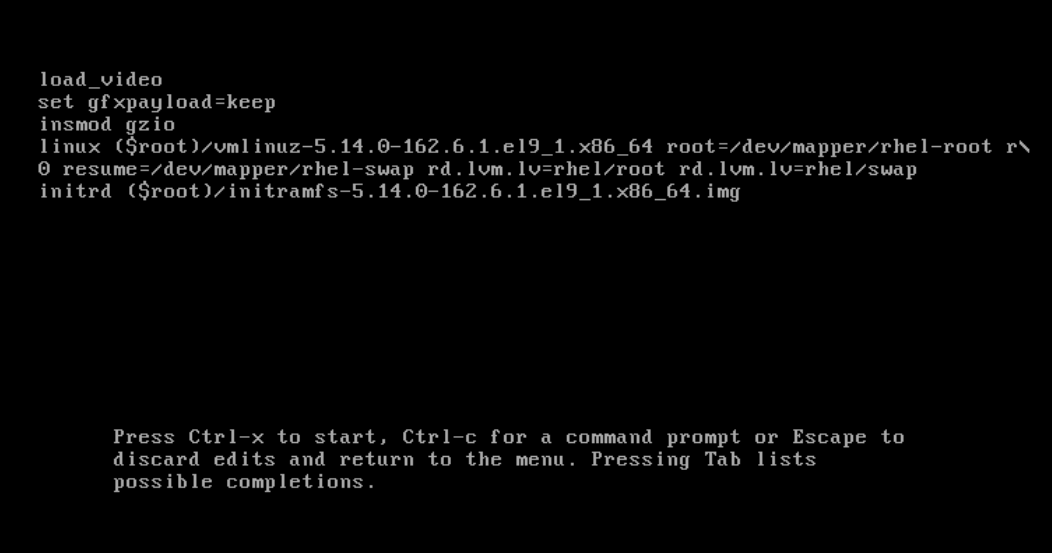
# mount -o remount,rw /sysroot
# chroot /sysroot # echo redhat | passwd –stdin root
# touch /.autorelabel
# sync
# exit
# exit
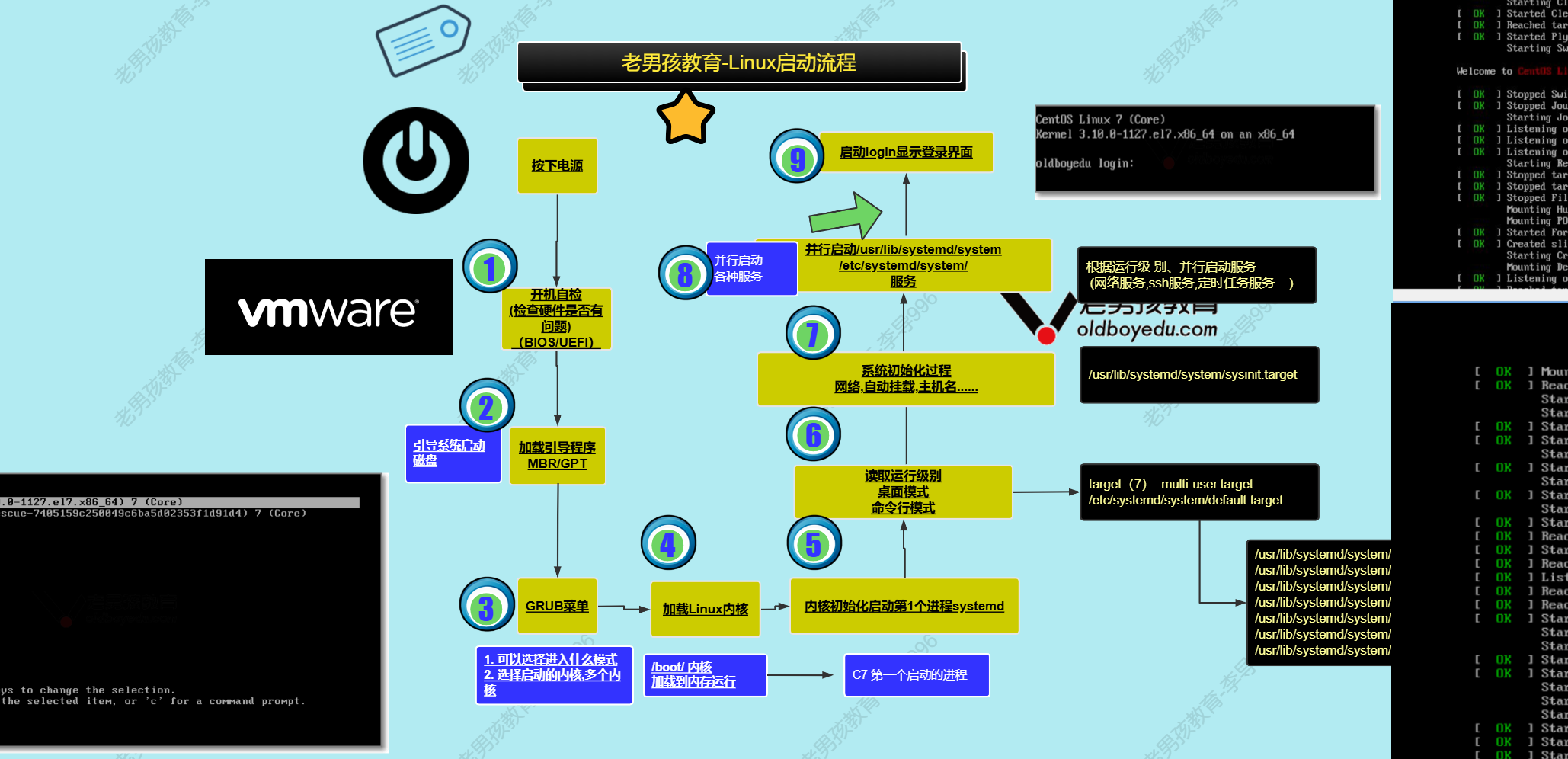
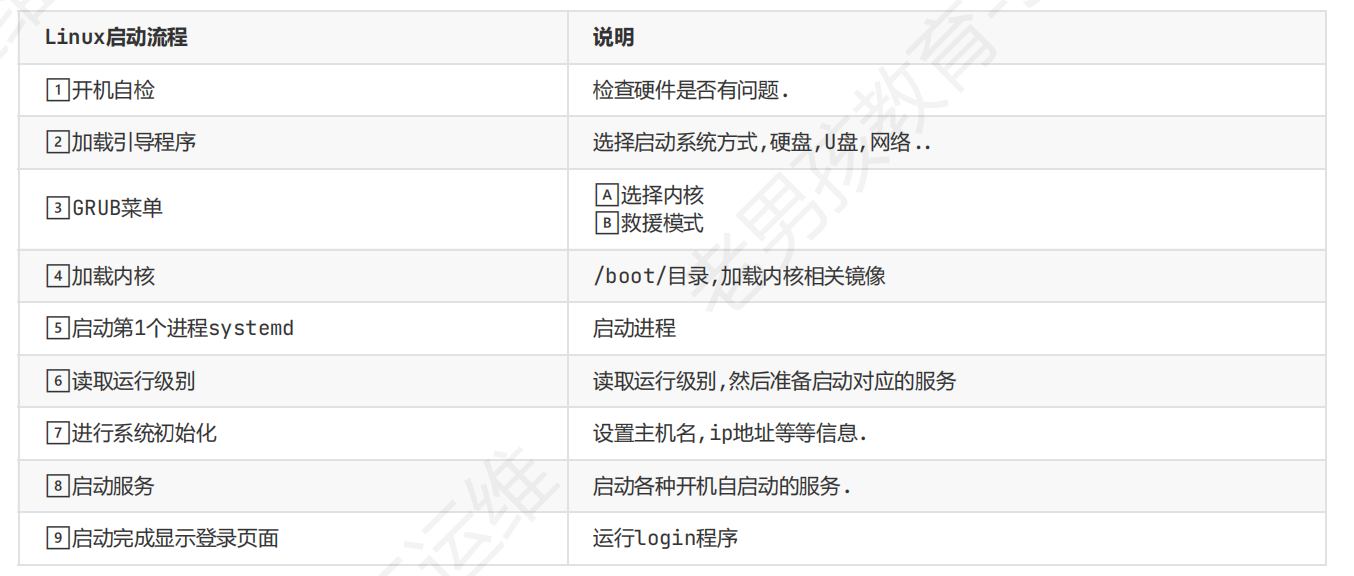
1.插入光盘
2.重启并在弹服务器logo时按esc进入boot菜单
3.选择光盘启动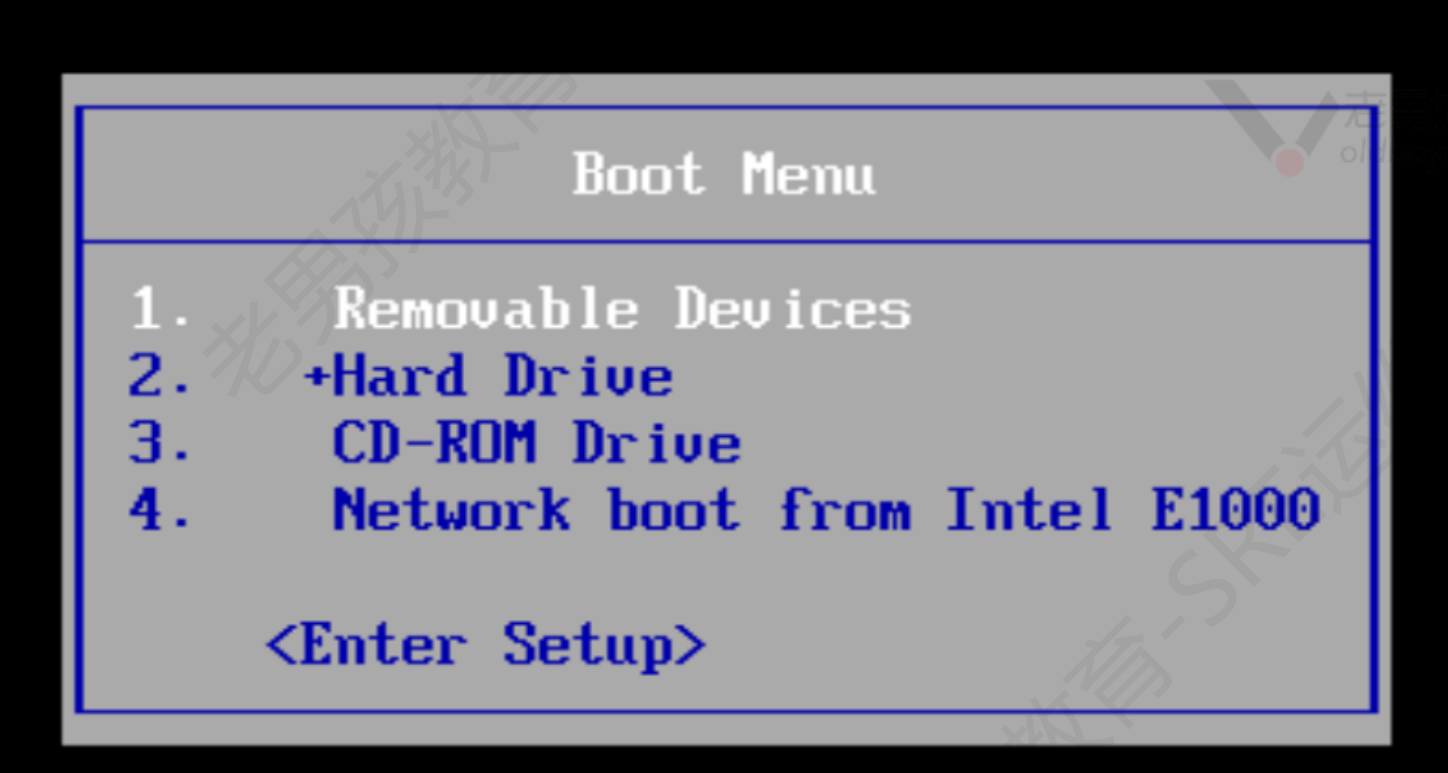
4.选troubleshooting→rescue的那行(install system)
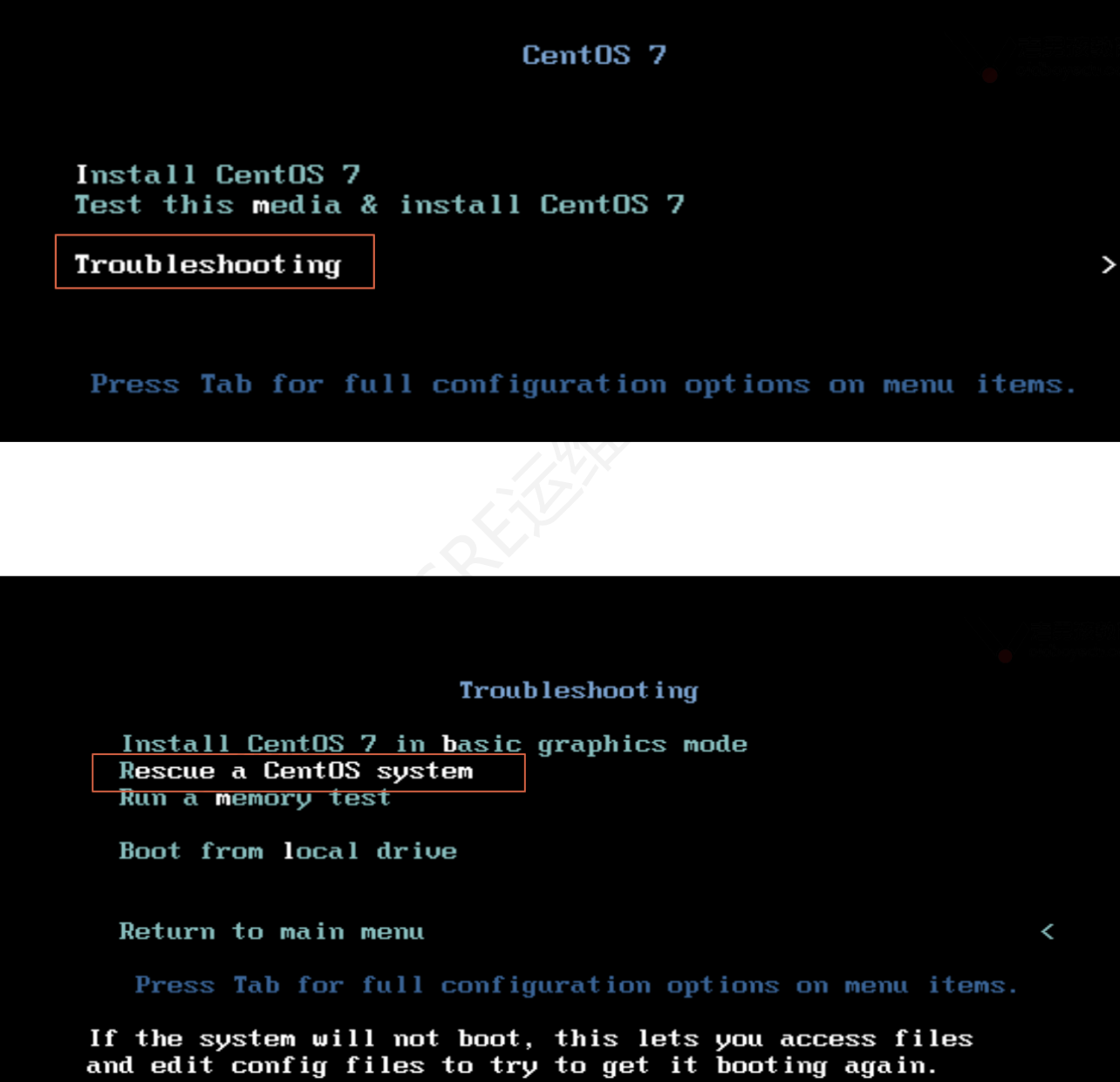
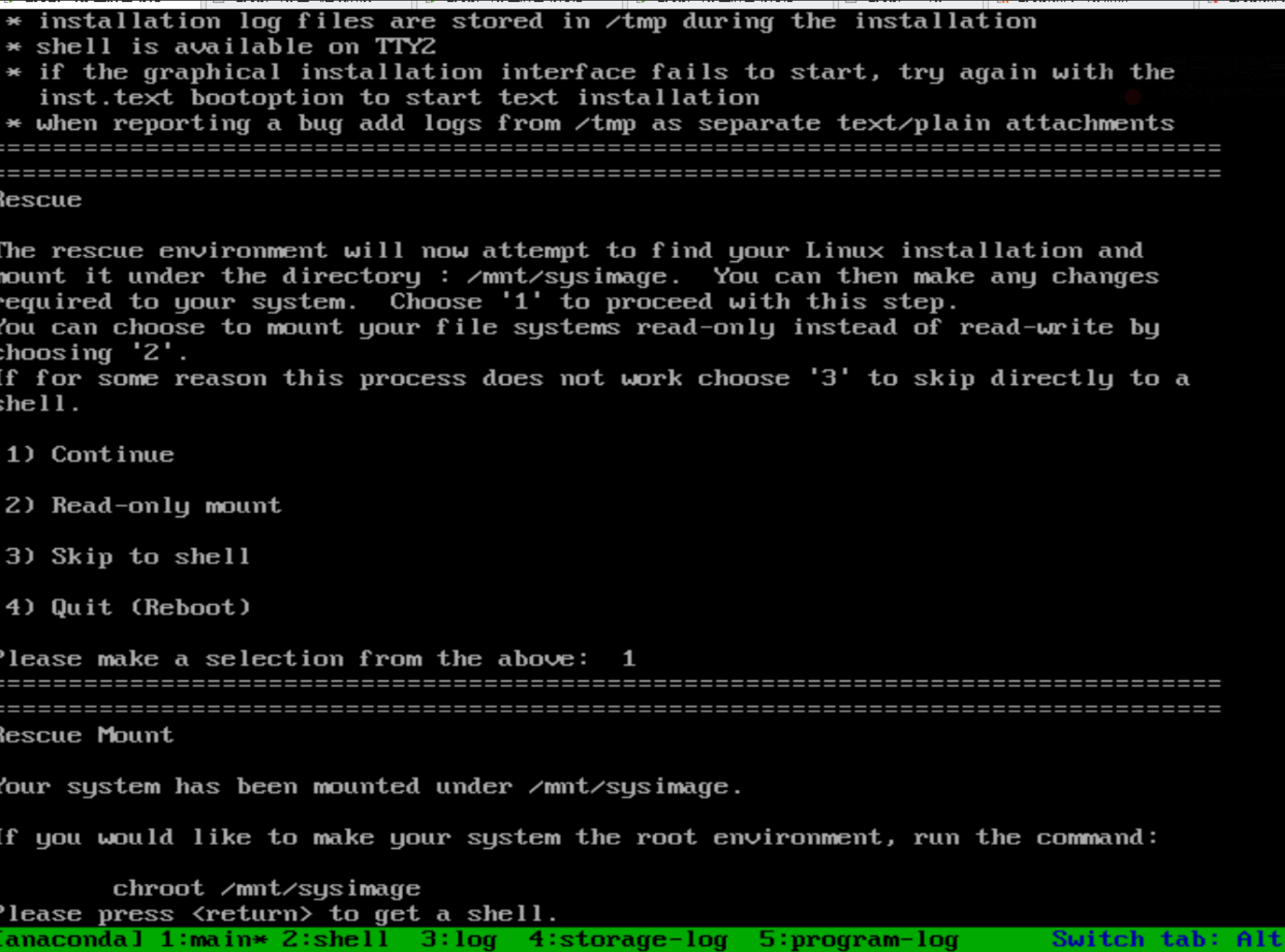
5.coutinue→1 进入rescue mount后输入chroot/mnt/sysimage即可进入光盘目录,
(这一步的目的主动切换根目录,原系统的根是/mnt/sysimage)
1.chroot /mnt/sysimage
2.vim /etc/passwd或者echo mima | passwd –stdin root
2.U盘:可以用ventory做可启动u盘,里面支持大量镜像,主要给物理服务器用
centos7:
GRUB菜单按e,找到linux16的行,ro(read only)改为rw,这行最后添加init=/bin/bash(以命令解释器进入系统),ctrl+x进入救援模式,不用输入root密码,vim /etc/passwd 把root行的x删除,即可清空root密码,ctrl+d退出后进入系统修改root密码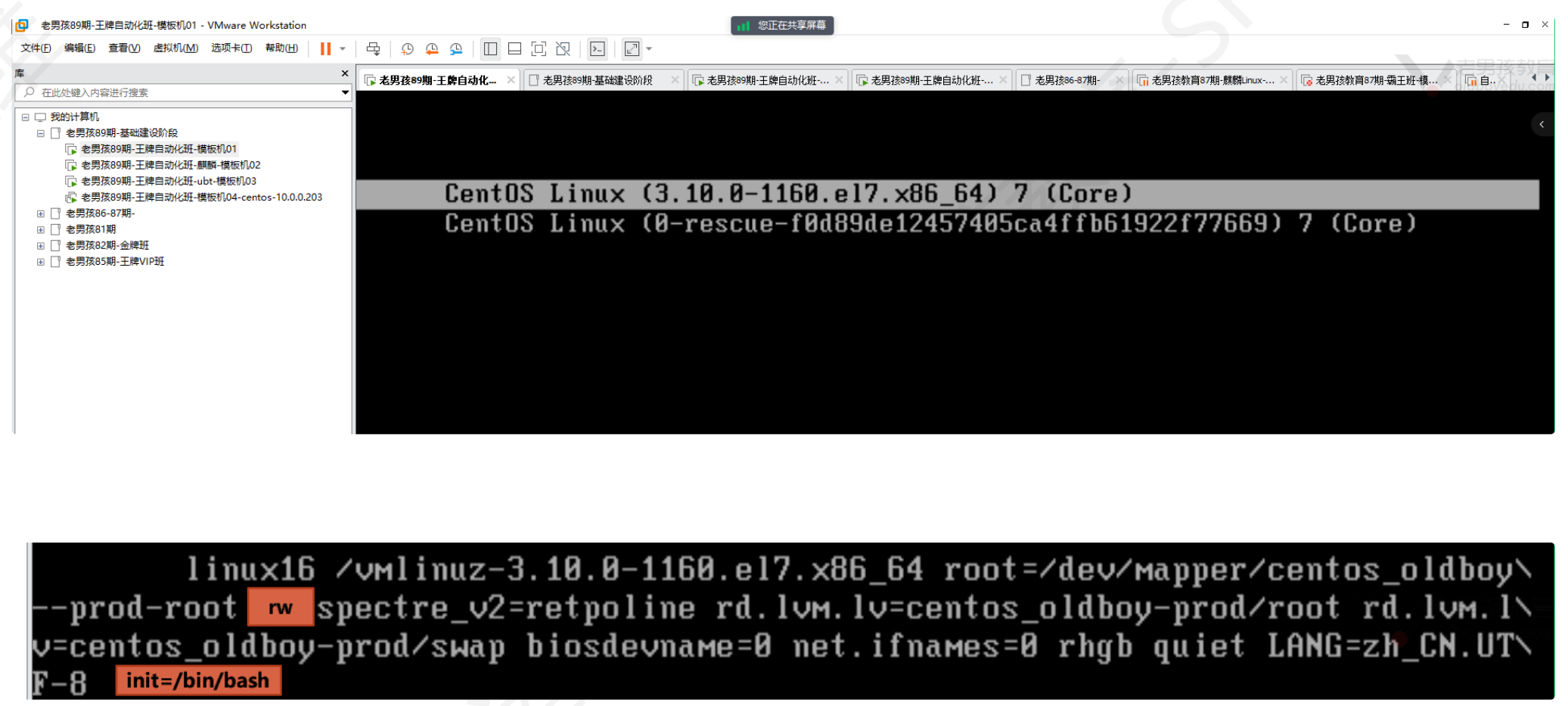
debian/ubt系:
默认不弹grub菜单,重启迅速按一下esc,出现boot menu界面在按一下esc,进入救援模式页面操作同上